20+ kafka data flow diagram
Learn how to use various big data tools like Kafka Zookeeper Spark HBase and Hadoop for real-time data aggregation. _____ is a programming model designed for processing large volumes of data in parallel by dividing the work into a set of independent tasks.
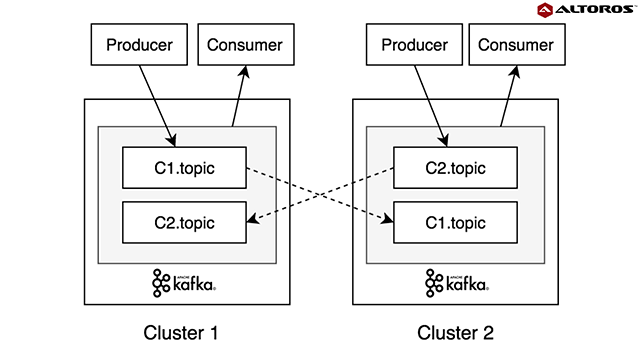
Multi Cluster Deployment Options For Apache Kafka Pros And Cons Altoros
Actions an a Data Model.
. 17 Interest-rates and the price of time. This example uses the sample dataset from the Search Tutorial and a field lookup to add more information to the event data. A Hive b MapReduce c Pig d Lucene View Answer.
The software allows one to explore the available data understand and analyze complex relationships. Event Hubs with Standard tier pricing and one partition should produce throughput between 1 MBps and 20 MBps. In Kafka brokers store event data and offsets in files.
8013 Kafka Data Model contd 0034. Set is a configuration input. The data will flow directly from the DataNode to the client.
The following diagram depicts the conceptual flow. Diagram is mostly based on this one others found online. An isentropic compression an isobaric constant pressure combustion an isentropic expansion and heat rejection.
A full production-grade architecture will consist of multiple Elasticsearch nodes perhaps multiple Logstash instances an archiving mechanism an alerting plugin and a full replication across regions or segments of your data center for high availability. Data Analysis Software tool that has the statistical and analytical capability of inspecting cleaning transforming and modelling data with an aim of deriving important information for decision-making purposes. Within the Kafka cluster some nodes in the cluster are designated as brokers.
The outbox pattern implemented via change data capture is a proven approach for addressing the concern of data exchange between microservices. Controller parses this DTO maps it to a CommandQuery object. Create a New Data Model.
Download the CSV file from Use field lookups tutorial and follow the instructions to set up the lookup definition to add price and productName to the. When a client or application receives all the blocks of the file it combines these blocks into the form of an original file. For this component it sets a keyword to scan for.
Changes the name of the Data Model. For example if your providers ID is uaa the property would be springclouddataflowsecurityauthorizationprovider-role-mappingsuaamap-oauth-scopes. You can use these archived files to rollback flow configuration.
8014 Kafka Architecture 0036. This set of Hadoop Multiple Choice Questions Answers MCQs focuses on Data Flow. Go through the HDFS read and write operation article to study how the.
In a clustered environment stop the entire NiFi cluster replace the flowxmlgz of one of nodes and restart the node. Defines who can use the Data Model in other applications. To search for data from now and go back in time 5 minutes use earliest-5m.
The number of Event Logs per Data Model is displayed to give you a better overview. Together these make up the Brayton cycle. Now let us go through Kafka-Spark APIs in detail.
Open the Data Model by clicking on the tile. The Kafka server is run as a cluster of machines that client applications interact with to read write and process events. The saga pattern as demonstrated in this article.
This is of course a simplified diagram for the sake of illustration. In is the main input. Explore what is real-time data processing the architecture of a big data project and data flow by working on a sample of big data.
At the center of the diagram is a box labeled Kafka Cluster or Event Hub Namespace. To search for data between 2 and 4 hours ago use earliest-4h latest-2h. Building a cash-flow projection for a fixed-coupon bond 0019.
Get trained by globally acclaimed Certified Scrum Trainers CSTs with Free Exam Retake. Also explore other alternatives like Apache Hadoop and Spark RDD. It has 3 input ports and 1 output port.
To search for data from now and go back 40 seconds use earliest-40s. Remove flowxmlgz from other nodes. In an ideal gas turbine gases undergo four thermodynamic processes.
It represents configuration for a Spark application. To do so stop NiFi replace flowxmlgz with a desired backup copy then restart NiFi. Type is another configuration input which assigns a specific type string with that keyword.
In a real gas turbine mechanical energy is changed irreversibly due to internal friction and turbulence into pressure and thermal energy. The more partitions you use the more open. Once the data is processed Spark Streaming could be publishing results into yet another Kafka topic or store in HDFS databases or dashboards.
Three smaller boxes sit inside that box. You can use Kafka to decouple applications send and receive messages track activities aggregate log data and process streams. Download the data set from Add data tutorial and follow the instructions to load the tutorial data.
RequestCLI commandevent is sent to the controller using plain DTO. Alternatively you can have Spring Cloud Data Flow map OAuth2 scopes to Data Flow roles by setting the boolean property map-oauth-scopes for your provider to true the default is false. In short data flow looks like this from left to right.
What are Data Analysis Software. 8015 Kafka Architecture contd. In this example we have a process called ScanInport which is an instance of a component called ScanKeyword from the dsl package.
20 PDUs and 16 SEUs. Once you confirmed the node starts.

Apache Kafka Data Flow Structure Download Scientific Diagram
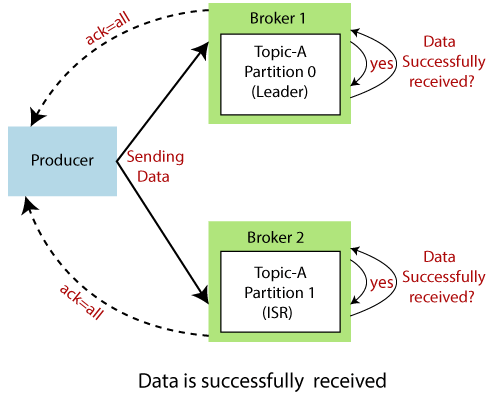
Apache Kafka What Is And How It Works By Joao Guilherme Berti Sczip The Startup Medium

Apache Kafka Data Flow Structure Download Scientific Diagram
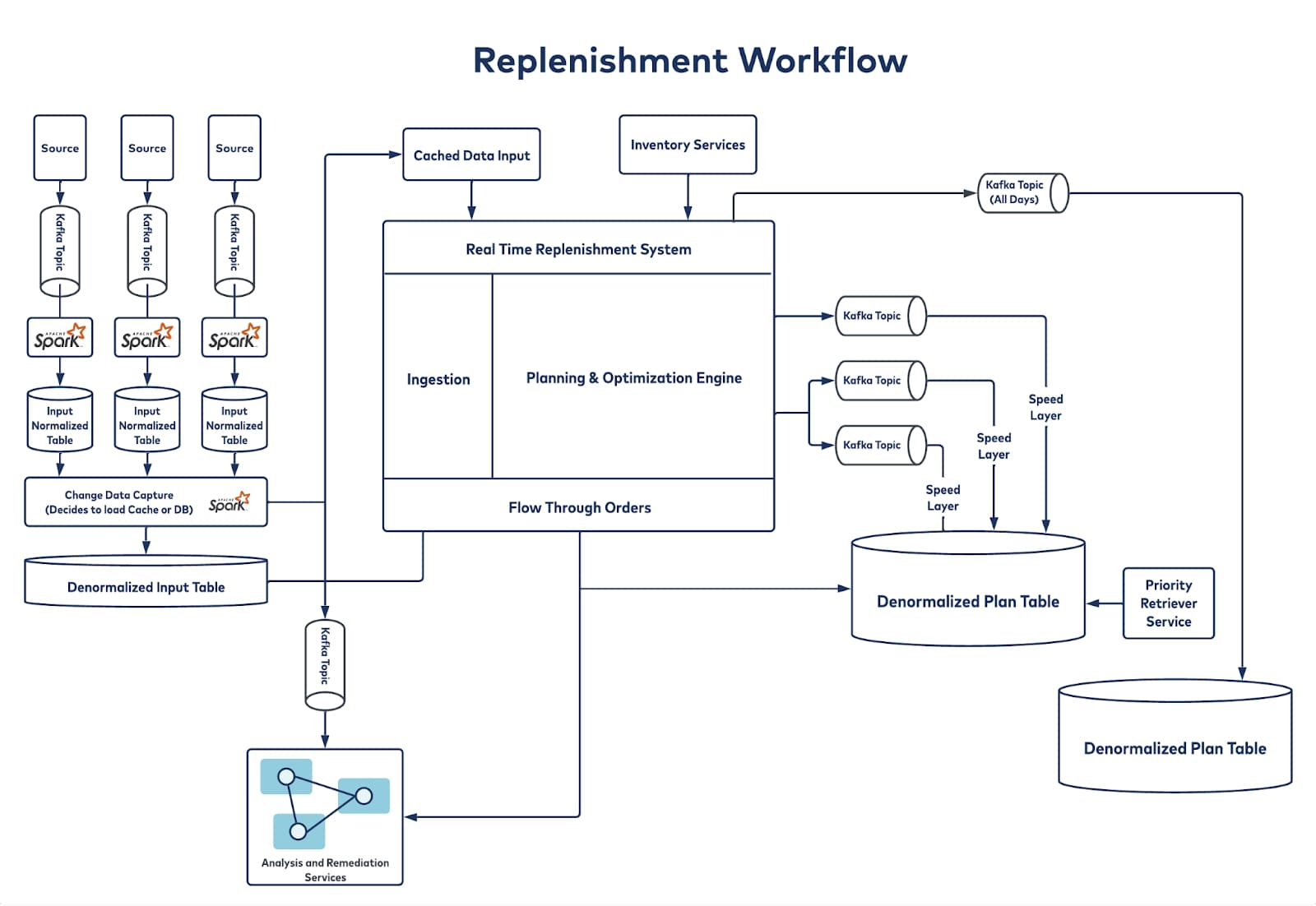
How Walmart Uses Apache Kafka For Real Time Replenishment At Scale Confluent How Walmart Uses Apache Kafka For Real Time Omnichannel Replenishment De
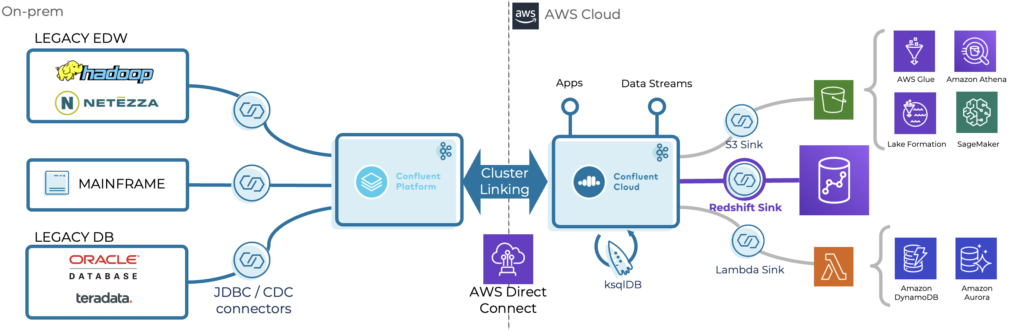
Serverless Kafka In A Cloud Native Data Lake Architecture Kai Waehner
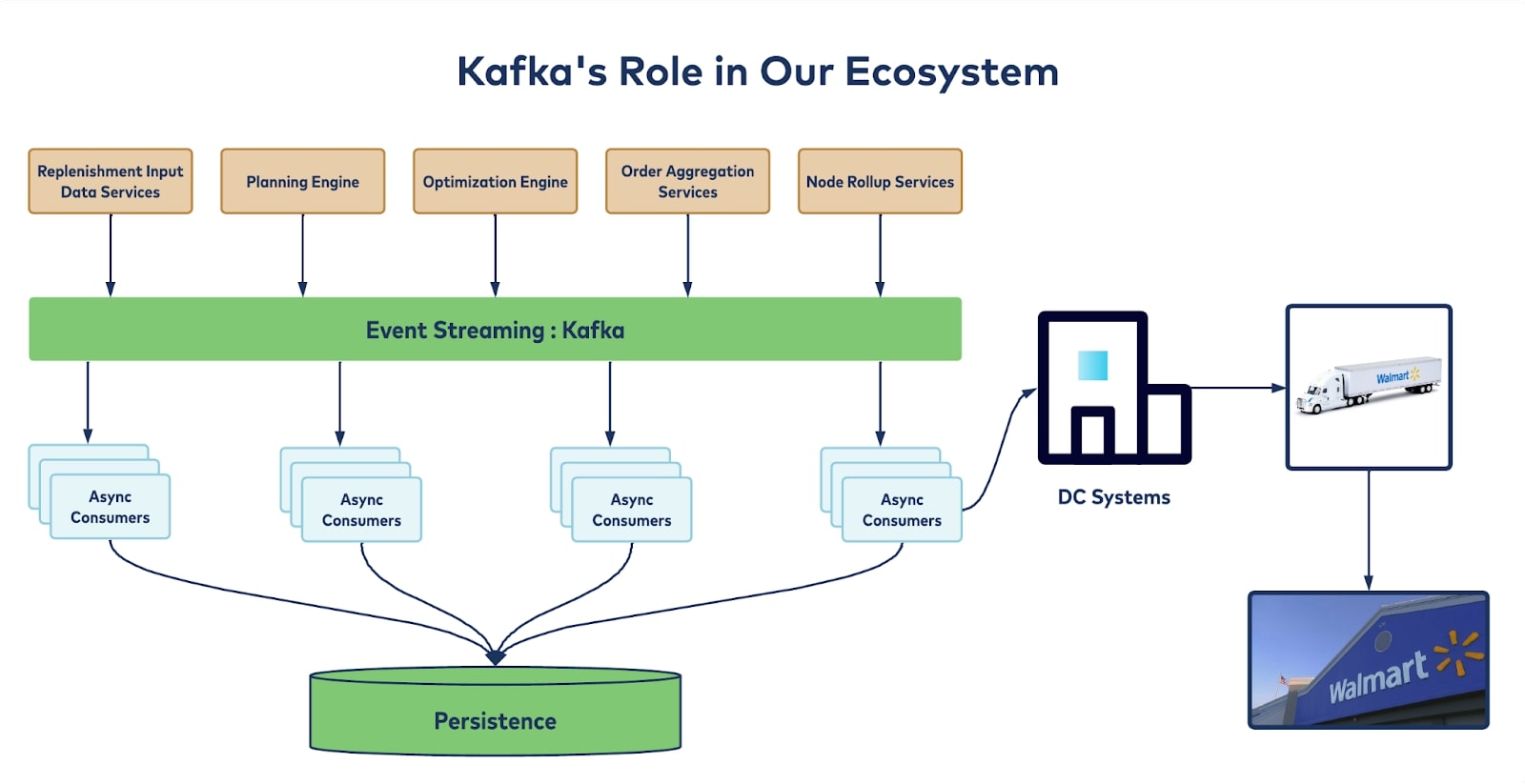
How Walmart Uses Apache Kafka For Real Time Replenishment At Scale Confluent How Walmart Uses Apache Kafka For Real Time Omnichannel Replenishment De
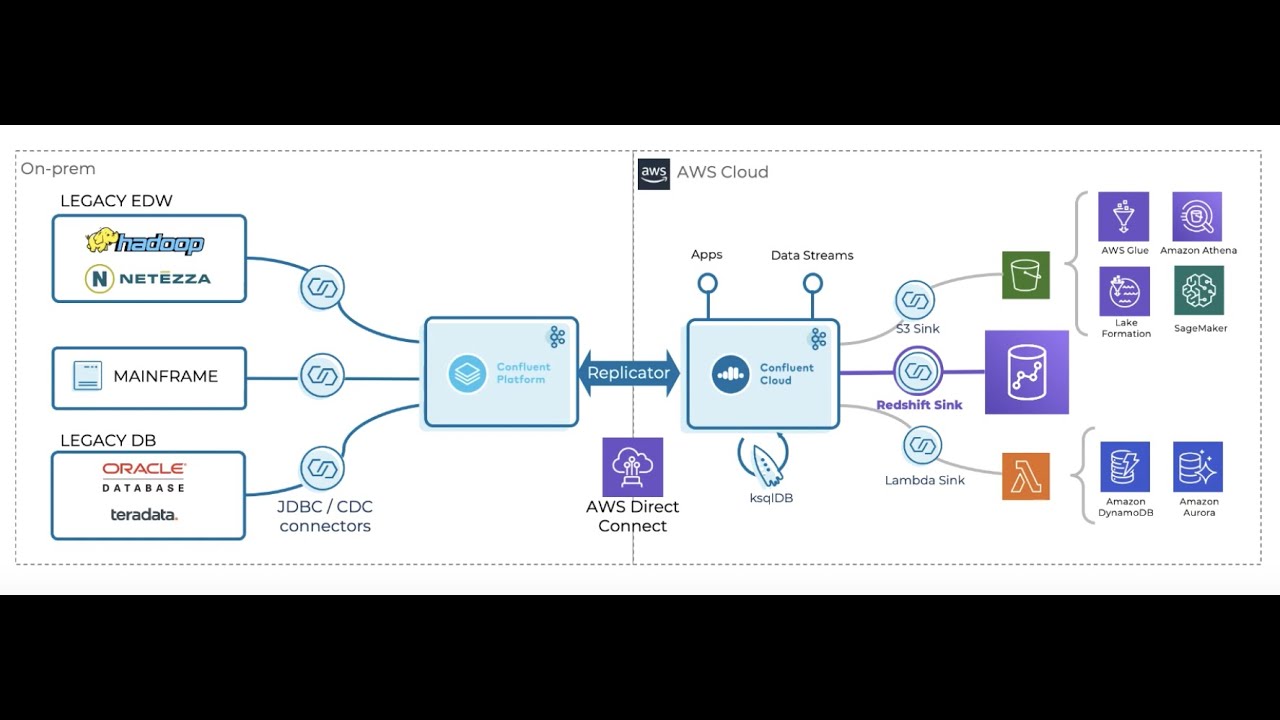
Serverless Kafka In A Cloud Native Data Lake Architecture Kai Waehner
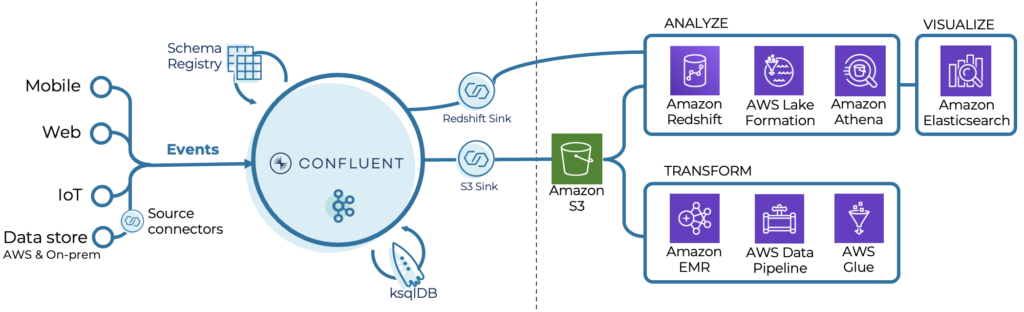
Serverless Kafka In A Cloud Native Data Lake Architecture Kai Waehner
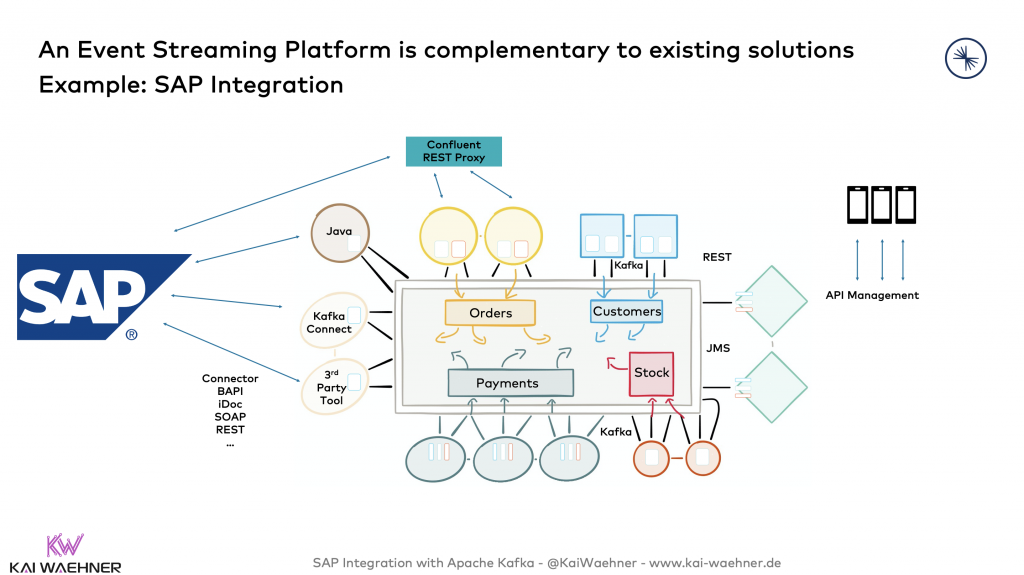
Kafka Sap Integration Apis Tools Connector Erp Et Al Kai Waehner

Data Flow Diagram Showing The Interaction Of The Mobile Application Download High Quality Scientific Diagram
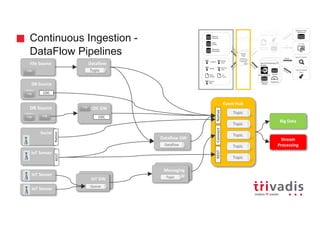
Self Service Data Ingestion Using Nifi Streamsets Kafka

Data Engineering Best Practices How Big Tech Faang Firms Manage And Optimize Apache Kafka

Putting Apache Kafka To Use A Practical Guide To Building A Streaming Platform Apache Kafka Computer Science Programming Data Architecture

System Architecture Overview Apache Kafka Provides The Central Download Scientific Diagram
Data Flow Diagram Showing The Interaction Of The Mobile Application Download High Quality Scientific Diagram

Flow Diagram For The Multilevel Streaming Analytics Framework Download Scientific Diagram
Streaming Use Cases For Snowflake With Kafka Snowflake